Atrium Integrator Connections - Workaround to Stop the Pain
If you are using Atrium Integrator in your ITSM System I’m sure you already had issues with connections.
Maybe you also made the mistake and you created more than one connection, for each of your environments [dev,qa,prod] and ended up in changing all the connections for each step, while staging them to another environment.
At on premise systems it already helps, if you are using one connection with the same name in all stages, and your Spoon UI is configured to not overwrite connections while importing transformations. (which needs to be set in every single Spoon UI)
But dealing with AI connections in Helix environment became much more complicated than I’ve ever expected.
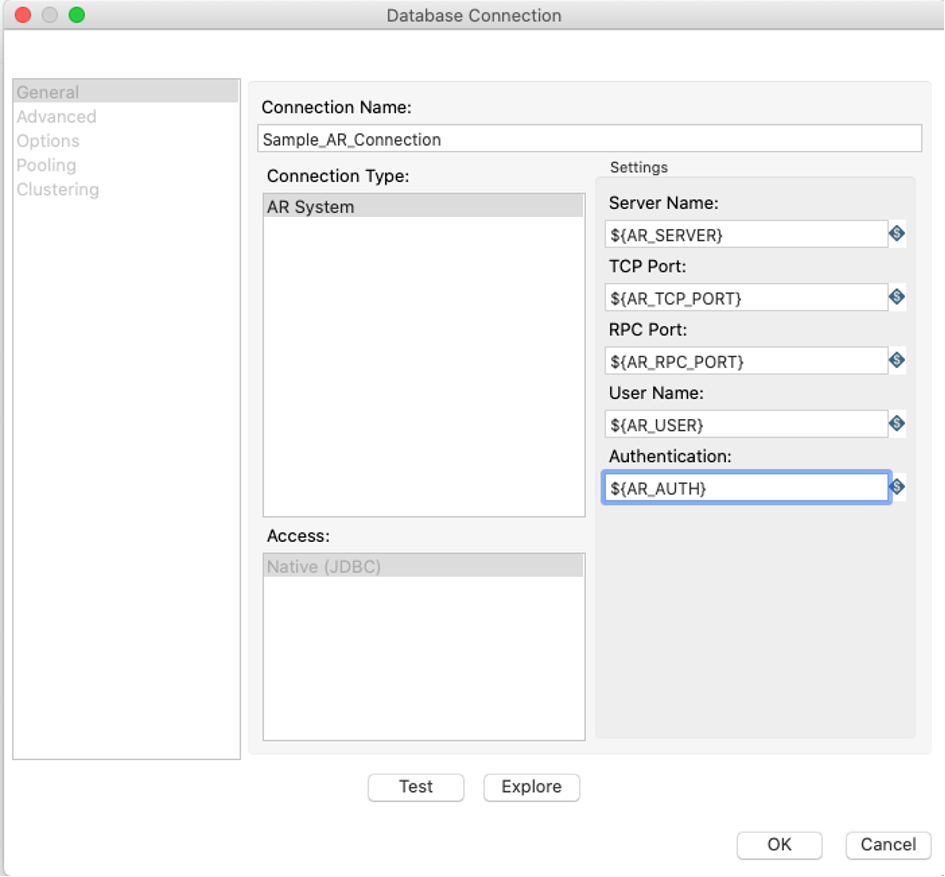
We can develop and debug the AI jobs in our system using a client gateway to the Helix server, but you need to use different connections for development/debug and serverside execution — even if you are working on the same stage!
This means if you have a transformation, which for example has 5 AR Input/AR Output, CMDB Output or AR Upsert/Table Input steps, and you need to do some debugging, to run the same job in Spoon you need to change ALL connections, do your debugging/change stuff and again change all connections back to run it on serverside.
It’s not hard to see that this will cause big problems, because maybe you will forget one or two steps.
How to get this solved?
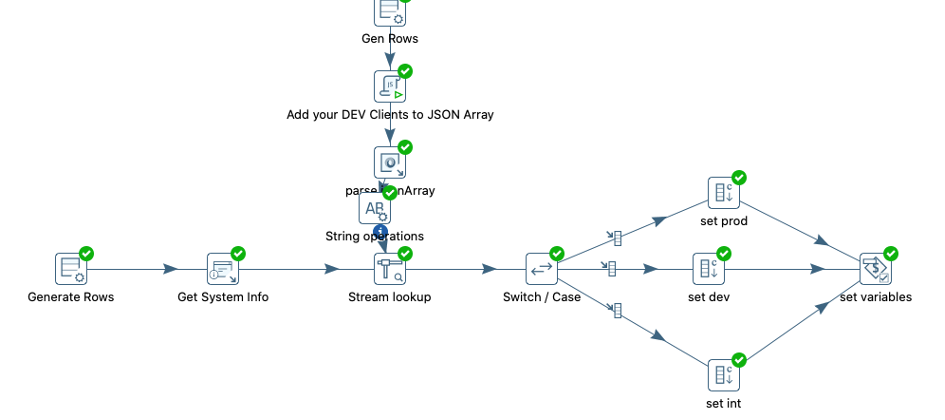
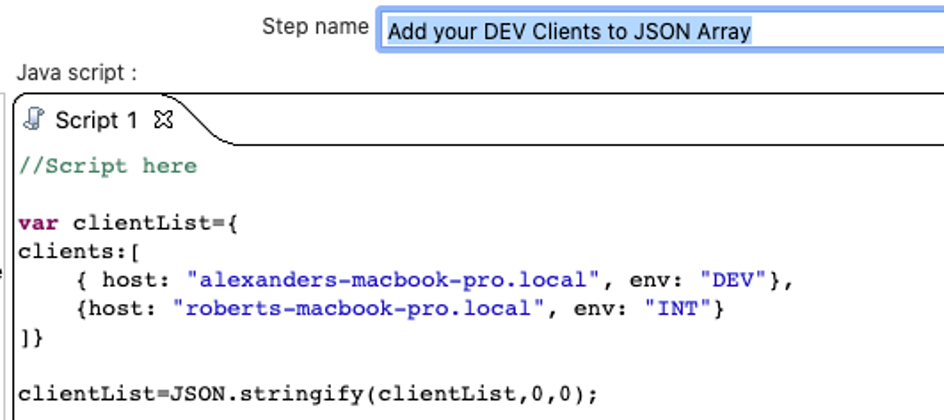
I’ve created a transformation which sets all your connections, depending on the system you run the transformations, by using variables.
IMPORTANT: This transformation needs to be the first transformation in each job to set the correct connection parameters for serverside executions. In your local dev system after opening Spoon you should run this transformation to set your connections.
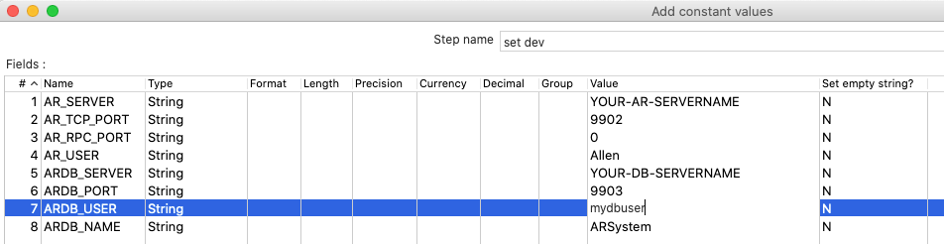
You can run it locally, on your client gateway, or on your server, on DEV, QA, Prod stage — it doesn’t matter — no more need to change connections. If you set up once.
Maybe you also had an idea to get this solved for your environment? How are you dealing with this?
Feel free to create a pull request if you also have a good idea.